For a workshop, I introduced the concept of classification without math or computer. I designed a problem involving pancakes of different shapes, colors, and flavors. In this post, I describe the setup and narrative I used.
How do you explain the basic concepts behind classification to complete beginners, without using a computer or any math?
My answer was to put participants in the shoes of a data scientist in front of a new problem. This problem involved pancakes.
Samples of pancakes shown to the participants.
The problem
To start the workshop, I pull pancakes out of my bag and say:
Yesterday I cooked pancakes but I mixed them all by mistake. These pancakes have different shapes, colors and flavors.
There are two flavors, orange and vanilla. I am allergic to orange and if I eat one I dye. Can you sort the vanilla pancakes for me?
But wait, you cannot give me half-eaten pancakes, it is rude! the only way to know the flavor of a pancake is to eat it all.
How would you approach this problem?
My role is then to guide them in finding out a solution to this problem. Along the way, I can introduce the concepts of data collection, feature extraction, classification boundaries, active learning, and even touch on bias of models.
The pancakes
The key is in the pancakes. I prepared them so that they have many different attributes, some of which predicting the flavor in a non-obvious way.
First I prepared pancakes with two flavors (orange and vanilla) and three colors (blue, green, red). Vanilla flavored pancakes are either red or blue, and orange ones are either red or green. Such that the color is not enough to predict the flavor but is a good starting point for participants to think about properties to flavors mapping.
Just cooked off
Pancakes bagged per flavor.
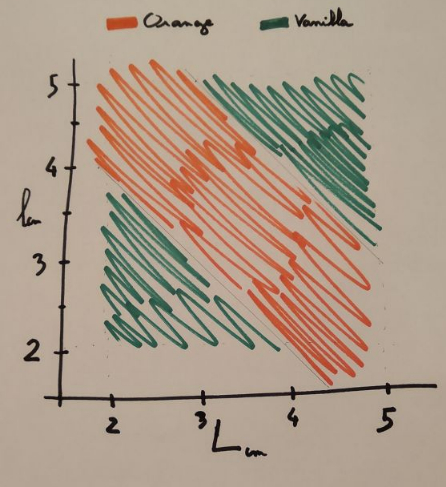
I also cut the pancakes in rectangular form of different length and width depending on their flavor and according to the following pattern.
The hidden relationship between pancakes length and width and their flavor.
The orange pancakes were cut in rectangles whose length and width stayed within the orange zone. For example, both a 3x4cm and a 5x2cm pancake would be of orange flavor. Respectively vanilla pancakes were cut to shapes within the green are, for example a 2x3cm and a 5×3.5cm would be vanilla flavor.
Samples of pancakes shown to the participants.
Now you understand that the shape of the pancakes is the key to predicting their flavor accurately. This mapping is not easy to infer by visually inspecting the pancakes, you really need to plot them to see the relationship.
The path to a solution
I left the participant think about the problem, manipulate pancakes and make their own hypothesis. After some initial brainstorming, we came up with the idea to create a table listing all the properties of the pancakes, including color, length, width and flavor.
They found out the color to flavor relationship (blue -> vanilla & green -> orange) but they got stuck with the red ones that were alternatively vanilla or orange flavor. I proposed to plot the properties we measured on the whiteboard.
Participant working out the shape to flavor relationship.
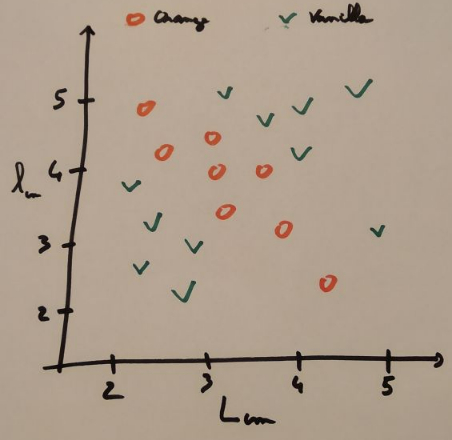
The plot looked like the figure below.
Scatter plot of pancakes width and length with flavors as labels.
They immediately understood that some areas were always containing vanilla pancakes and other orange pancakes. The question was now: where to draw the line between vanilla and orange?
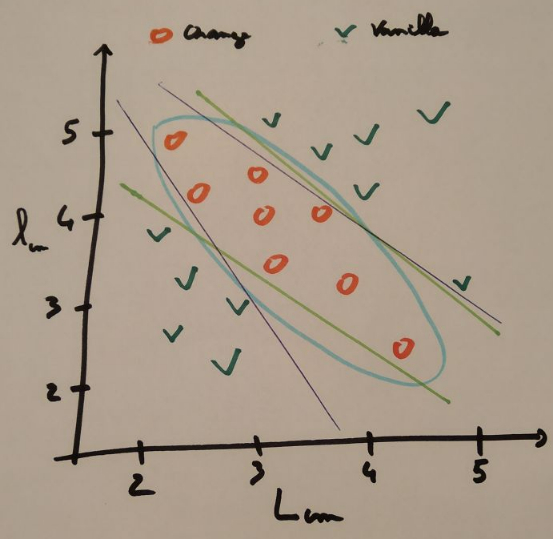
I told them to take a few minutes to think about it and then use pens of different color to draw that line. Each participant ended up drawing slightly different lines. I added a blue ellipse to show them another way to think about the classification boundary. And one participant even came up with a conditional equation much alike a decision tree classifier.
Classification boundaries as drawn by different participants.
And that is it, they reinvented for themselves the process behind classification.
I explained to them how each type of classification boundaries corresponds to different classification algorithms. Some algorithms make linear assumptions (logistic regression, LDA), some work in terms of neighbours or use kernels, and some define a hierarchical decision tree. They are all valid way to draw the line between classes, some methods will work better on different data but in the end, it is up to the data scientist to select between models.
They were then able to take new pancakes from the table and separate the vanilla from the orange one without eating them! I got to enjoy some vanilla pancakes and did not dye eating orange one, mission accomplished. Congratulations!
Going further
Machine learning pipeline
In the duration of this workshop, I could introduce the pipeline of all machine learning classification problems:
Decide on features to extract from the object
Build a dataset of features and labels for many objects
Train a classifier on the features and labels, i.e. draw the line between classes
Use the classifier/model to predict the class of new objects
Active learning
At this point, you can ask participants what they would do to increase their confidence in the line they drew to separate vanilla from orange. Indeed, they did not all agree about how to draw that line, and surely there must be a way to put them in agreement.
A solution is to collect more data. But not randomly of course, instead they could select the next pancake to eat carefully to increase their confidence. They could for example form a committee to select the pancake that would provide the most information to differentiate between their respective models.
This process is called active learning and many heuristics have been developed to select the next sample to collect.
Model bias, assumptions, and limitations
Finally, I wanted to challenge the power of their model by asking them to classify the pancakes shown below.
Pancakes not conforming to training set. What happens if you try to predict their flavor?
As we can see these pancakes do not conform with the pancakes they used to build the model. Trying to extract features on the triangle, circle, and flag shaped pancakes is possible but is likely to lead to wrong results. As for the non-colored pancakes, they have the same rectangular shape but they are very salty pancakes. Salty being neither vanilla nor orange, the model will not be able to predict that either.
Unfortunately, when the full pipeline is automated, it is very difficult to detect when the inputs are not conforming to our training data. A classification algorithm will always give back an answer, in our case vanilla or orange. It is our responsibility to interpret results with this in mind, use our best judgement and recognize the limitation of machine learning algorithms, especially where they might have real-world consequences.
Resources
Below are the slides I used during the workshop. All images have been found on the internet, thanks for those who shared them. For bias and limitations of mathematical models, I invite you to read Weapons of Math Destruction by Cathy O’Neil